CM Pivot Internals
CM Pivot Internals
CM Pivot is one of the coolest new features Microsoft has put in SCCM. In this blog, we are going to rip the covers off CM Pivot and look at how it works under the scenes. This information will help you understand results as they come back from CM Pivot, and hopefully help you avoid issues with the product as you start to use it more and more in your environment.
Getting started
If you are looking for a quick start guide on CM Pivot, look no further than the Microsoft Docs. These should get you started! This post will assume you know a little about CM Pivot already.
Client Side
I wanted to start with client side because this is the most eye-opening piece we’ll be talking about. Knowing how CM Pivot works on clients is vital to understanding the data you have coming back.
CM Scripts
Microsoft has said a few times that CM Pivot is built on scripts, which is a nice way of saying the client-side piece of CM Pivot is a PowerShell script. You heard that right, when you type your query in the CM Pivot window, it triggers a CM Script with parameters and sends that to the client. What script does it trigger? The one called CMPivot!
If you want the text of this script, here’s a quick SQL query to get the script:
SELECT CONVERT(varchar(max), Script) as 'ScriptText'
FROM Scripts
WHERE ScriptName = 'CMPivot'
If you run this query, you’ll see a large script that accepts two parameters and if you read through you’ll find the logic for all parts of CM Pivot. How do they query WMI? How do they parse logs? It’s all right here.
Why does this matter? If you look at the script, you’ll start noticing something. There’s no filters on the script! There are some parameters it can take (for instance, what log file do we want to read?), but there is no way on the client side to limit the data sent back from the CM Pivot query.
CM Pivot Queries
What does this mean? Let’s look at an example I’ll steal from SystemCenterDudes CM Pivot example queries. Note, this is a fantasic page and I reference it a lot. I’m going to pick on one specific query on the page, but it is still a good query, it’s just not obvious whats happening.
Here’s the query:
List 50 last lines of a specific SCCM log file on a specific computer:
CcmLog('Scripts') | where (Device == 'DeviceName') | order by DateTime desc | project Device, LogText, DateTime
This query when run as-is will return no results. Why? You probably don’t have a device named DeviceName in your organization. You’ll see results like this:
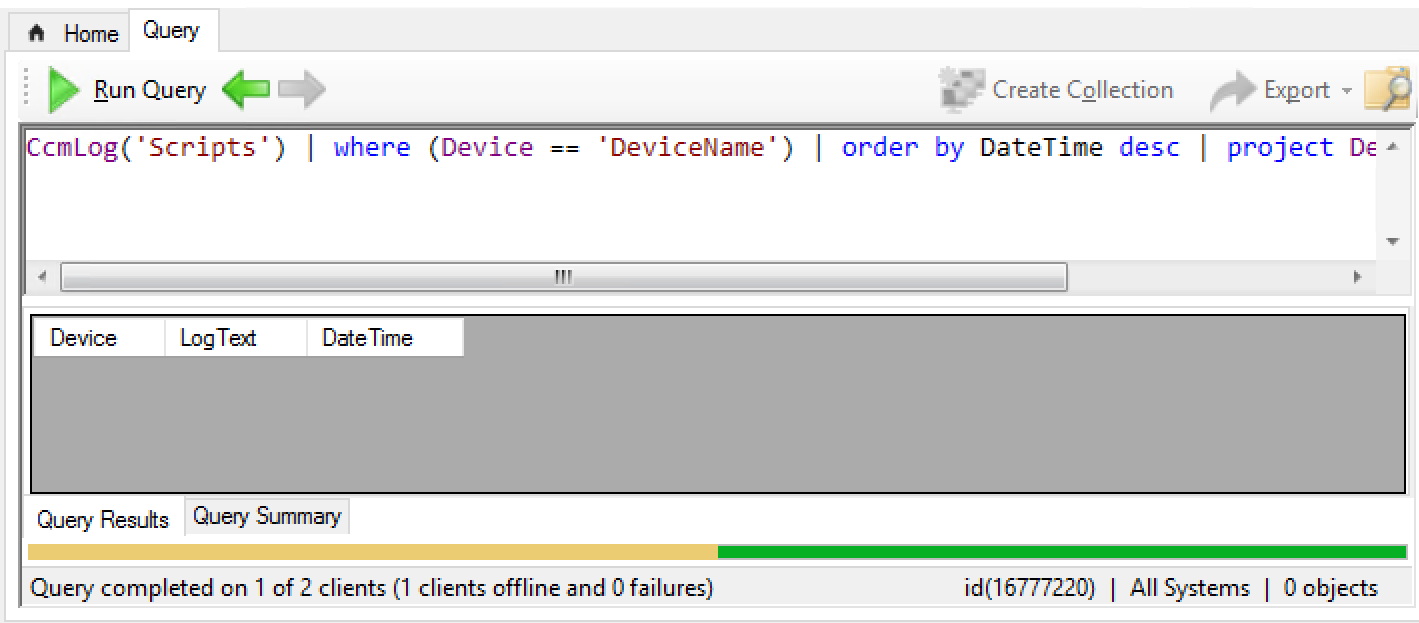
If I query SQL with this query:
SELECT [ResourceID]
,[ScriptOutput]
,[LastUpdateTime]
FROM [vSMS_CMPivotResult]
ORDER BY LastUpdateTime DESC
Now, I see results for all systems I queried! What’s going on? In a CM Pivot query, the only thing you can send to clients to filter results client side is to the left of the first |. This means the filter “where (Device == ‘DeviceName’)” is only processed AFTER the results come in. If this query was run against “All Systems”, every single system in your environment will run the CM Pivot query, send back the last 50 lines of the Scripts log file, put that in SQL, and then do nothing with it because the Device I wanted wasn’t there.
Note, this isn’t a dig at CM Pivot - it’s understanding how the technology works so good decisions can be made. Let’s look at an example where this could give us potentially wrong information:
EventLog('System') | where Source == 'Iphlpsvc'
In this query, I think I’m searching the event log of all my systems for the source ‘Iphlpsvc’. But remember, only the pieces on the left of the first | get sent to the client, so what actually happens? Every client sends back the newest 50 records in the System Event Log, and then in SQL the results are filtered and displayed based only on the newest 50 records. So since the System Event log is much larger than 50 records, it’s not a true search. I could very easily think this source isn’t recorded in any device in my organization, but it could in fact be in all of them.
Data Layer
We’ve talked a little about CM Pivot and SQL in the queries section, but I did want take a moment to talk about what happens on SQL.
SQL is used to temporarily store all CM Pivot results pre-filter. If you wanted to dig into the results, the view vSMS_CMPivotResult is where you’d go to look at Pivot results. CM Pivot is meant to be live, so no historical results are saved. When you close the UI, the data is cleared out. If there is any orphaned data, it will be cleared within 7 days.
Conclusion
CM Pivot is an amazing addition to our toolkit and it has a bright future, however it does have limits and some quirks about it. Hopefully this blog post will help you use make good decisions with CM Pivot so you can get the most out of it!
Leave a Comment